OpenAI ファインチューニング
Weights & Biases を使用して、OpenAI GPT-3.5 や GPT-4 モデルのファインチューニングのメトリクスや設定をログに記録し、パフォーマンスを分析・理解して、新しくファインチューニングされたモデルの結果を同僚と共有できます。ファインチューニング可能なモデルはこちらから確認できます。
Weights and Biases ファインチューニング統合は openai >= 1.0 で動作します。最新バージョンの openai をインストールするには、pip install -U openai を実行してください。
OpenAI ファインチューニングの結果を2行で同期
OpenAIのAPIを使用してOpenAIモデルをファインチューニングする場合、W&Bのインテグレーションを使用して、Experiments、Models、Datasetsを中央のダッシュボードで追跡できます。
from wandb.integration.openai.fine_tuning import WandbLogger
# ファインチューニングのロジック
WandbLogger.sync(fine_tune_job_id=FINETUNE_JOB_ID)
インタラクティブな例をチェック
数行のコードでファインチューンを同期
openai と wandb の最新バージョンを使用していることを確認してください。
pip install --upgrade openai wandb
その後、スクリプトから結果を同期します
from wandb.integration.openai.fine_tuning import WandbLogger
# ワンラインコマンド
WandbLogger.sync()
# オプションのパラメータを渡す
WandbLogger.sync(
fine_tune_job_id=None,
num_fine_tunes=None,
project="OpenAI-Fine-Tune",
entity=None,
overwrite=False,
model_artifact_name="model-metadata",
model_artifact_type="model",
**kwargs_wandb_init
)
リファレンス
| 引数 | 説明 |
|---|---|
| fine_tune_job_id | これは、client.fine_tuning.jobs.create を使用してファインチューンジョブを作成すると取得できる OpenAI ファインチューン ID です。この引数が None(デフォルト)の場合、既に同期されていないすべての OpenAI ファインチューンジョブが W&B に同期されます。 |
| openai_client | 初期化された OpenAI クライアントを sync に渡します。クライアントが提供されない場合、ロガー自体が初期化します。デフォルトは None です。 |
| num_fine_tunes | ID が提供されていない場合、同期されていないすべてのファインチューンが W&B にログされます。この引数は、同期する最近のファインチューンの数を選択するためのものです。num_fine_tunes が 5 の場合、最新の 5 つのファインチューンが選択されます。 |
| project | Weights and Biases プロジェクト名。ここにファインチューンのメトリクス、モデル、データなどがログされます。デフォルトでは、プロジェクト名は "OpenAI-Fine-Tune" です。 |
| entity | Weights & Biases ユーザー名またはチーム名。ここに実行が送信されます。デフォルトでは、デフォルトのエンティティが使用され、通常はユーザー名です。 |
| overwrite | 同一のファインチューンジョブの既存の wandb run を上書きしてログを強制します。デフォルトでは False です。 |
| wait_for_job_success | 一度 OpenAI ファインチューンジョブが開始されると、通常少し時間がかかります。この設定は、ファインチューンジョブのステータスが「成功」に変わるのを毎秒60秒チェックすることで、ファインチューンジョブが終了次第メトリクスがすぐに W&B にログされることを保証します。デフォルトで True 設定されています。 |
| model_artifact_name | ログされるモデルアーティファクトの名前。デフォルトは "model-metadata" です。 |
| model_artifact_type | ログされるモデルアーティファクトのタイプ。デフォルトは "model" です。 |
| **kwargs_wandb_init | wandb.init() に直接渡される追加の引数 |
Dataset のバージョン管理と可視化
バージョン管理
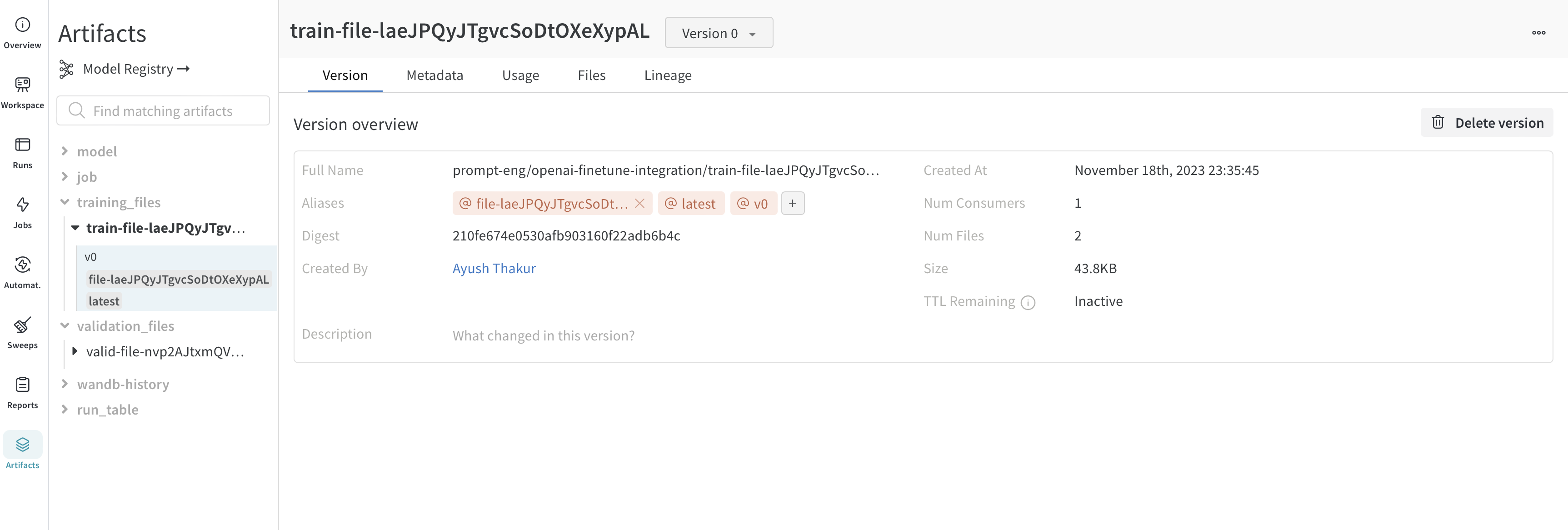
ファインチューンのために OpenAI にアップロードするトレーニングデータと検証データは、より簡単にバージョン管理できるように自動的に W&B Artifacts としてログされます。以下に、Artifacts にあるトレーニングファイルのビューを示します。ここでは、このファイルをログした W&B run、ログ日時、このデータセットのバージョン、メタデータ、およびトレーニングデータからトレーニング済みモデルまでのリネージを確認できます。
可視化
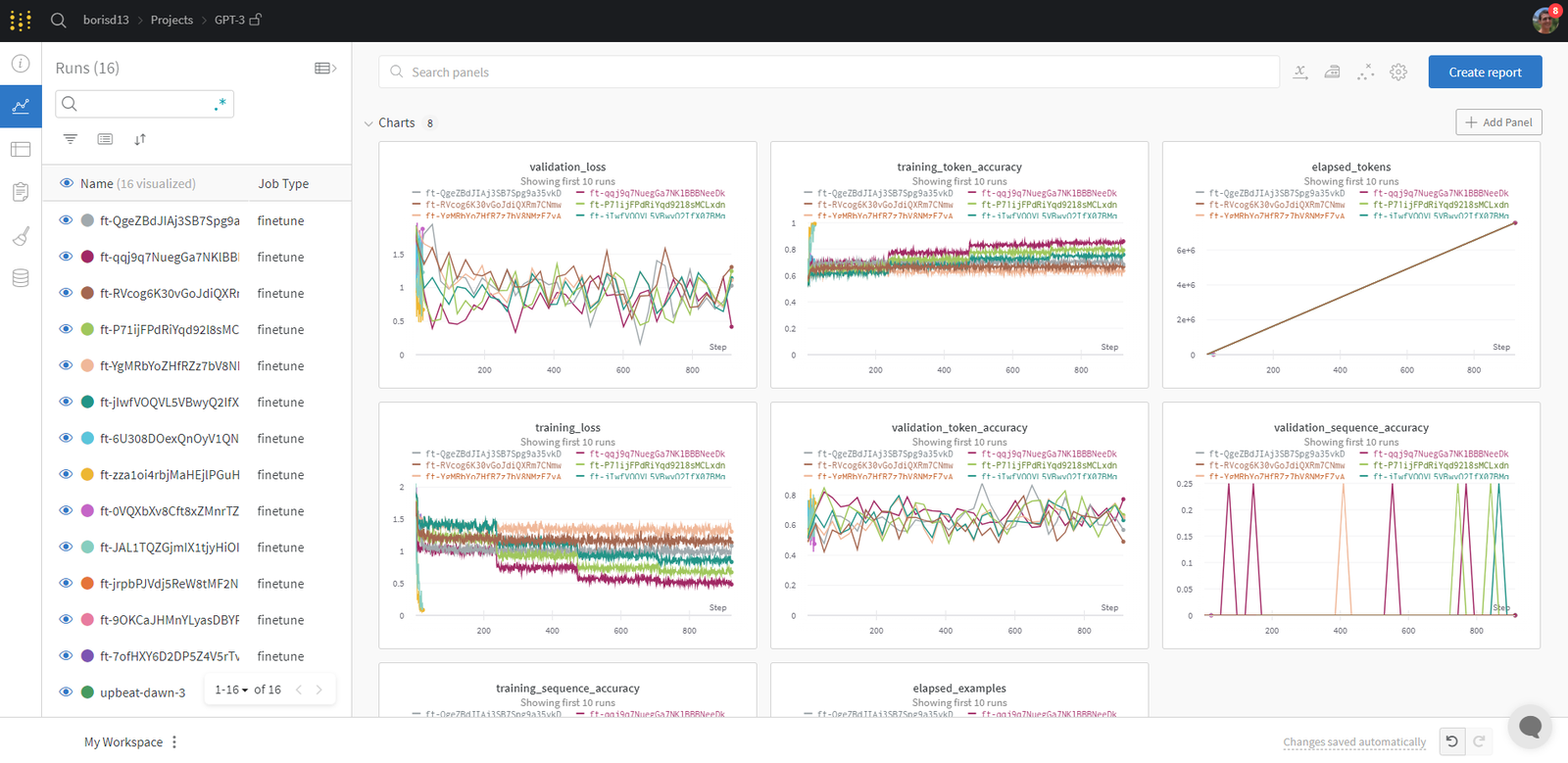
データセットは W&B Tables としても可視化され、データセットを探索、検索、および対話することができます。以下の W&B Tables を使用して可視化されたトレーニングサンプルをチェックしてください。

ファインチューニングモデルとモデルバージョン管理
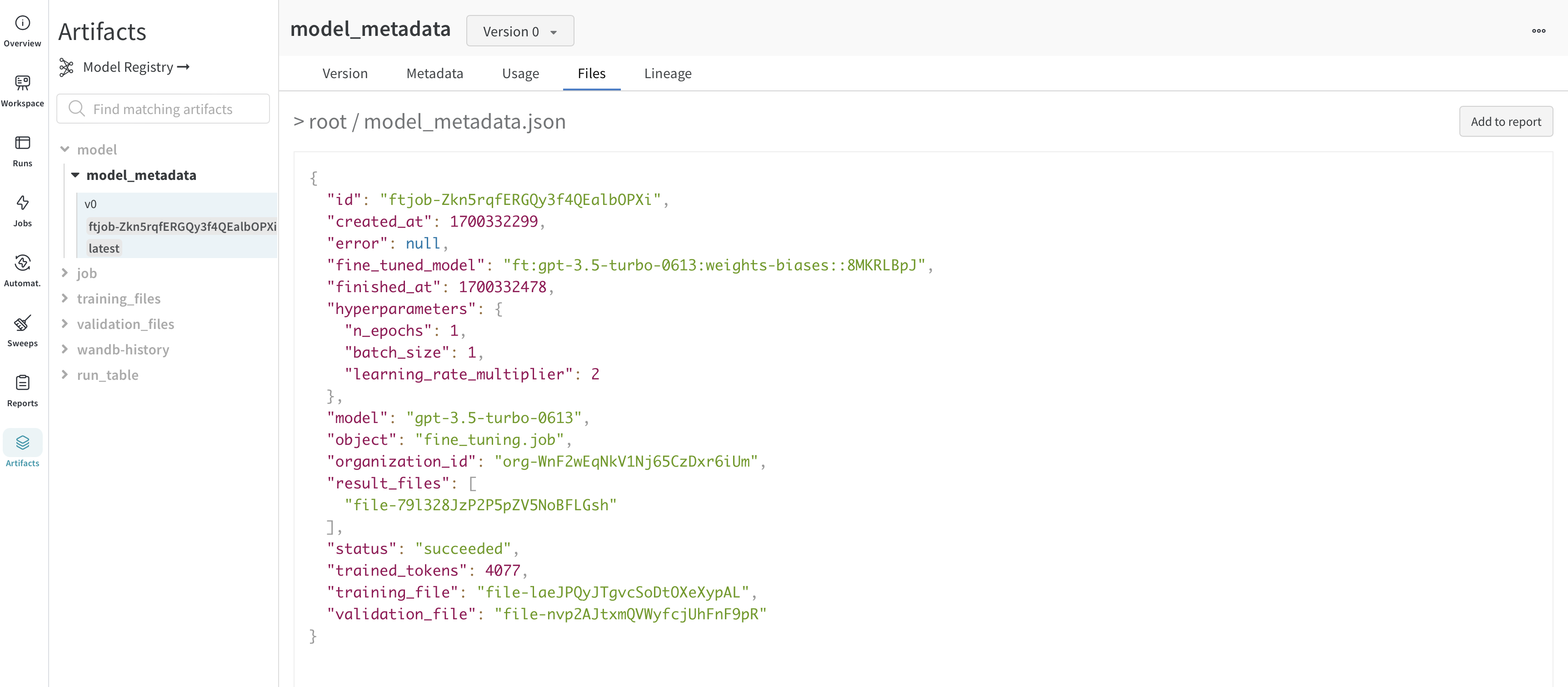
OpenAI はファインチューニングされたモデルのIDを提供します。モデルの重みを取得することはできませんが、WandbLogger は model_metadata.json ファイルを作成し、モデルの詳細(ハイパーパラメータ、データファイルIDなど)と fine_tuned_model ID を含め、W&B Artifact としてログします。
このモデル (メタデータ) アーティファクトは、W&B Model Registry のモデルにリンクされ、さらには W&B Launch とペアリングすることもできます。
よくある質問
ファインチューンの結果をチームと共有するにはどうすればいいですか?
ファインチューニングジョブをチームアカウントにログするには次のようにします:
WandbLogger.sync(entity="YOUR_TEAM_NAME")
Runs をどのように整理すればいいですか?
W&B runs は自動的に整理され、ジョブタイプ、ベースモデル、学習率、トレーニングファイル名、その他の任意のハイパーパラメータなどの設定パラメータに基づいてフィルター/ソートが可能です。
さらに、runs をリネームしたり、ノートを追加したりタグを作成してグループ化したりすることもできます。
納得がいったら、ワークスペースを保存し、runs と保存されたアーティファクト(トレーニング/検証ファイル)からデータをインポートしてレポートを作成できます。
ファインチューニングされたモデルにアクセスするにはどうすればいいですか?
ファインチューニングされたモデル ID は、アーティファクト (model_metadata.json) および設定として W&B にログされます。
import wandb
ft_artifact = wandb.run.use_artifact("ENTITY/PROJECT/model_metadata:VERSION")
artifact_dir = artifact.download()
ここで VERSION は次のいずれかです:
v2のようなバージョン番号ft-xxxxxxxxxのようなファインチューンID- 自動的に追加される
latestや手動で追加されるエイリアス
ダウンロードした model_metadata.json ファイルを読み取ることで fine_tuned_model ID にアクセスできます。
ファインチューンが正常に同期されなかった場合はどうすればいいですか?
ファインチューンが正常に W&B にログされていない場合は、overwrite=True を使用してファインチューンジョブIDを渡すことができます:
WandbLogger.sync(
fine_tune_job_id="FINE_TUNE_JOB_ID",
overwrite=True,
)
W&B でデータセットとモデルを追跡できますか?
トレーニングデータと検証データは自動的に W&B にアーティファクトとしてログされます。ファインチューンされたモデルの ID を含むメタデータもアーティファクトとしてログされます。
wandb.Artifact、wandb.log などの低レベルの wandb API を使用して、パイプラインを完全に制御することができます。これにより、データとモデルの完全な追跡性が確保されます。